
Guide de survie pour décideurs dans la jungle de l’IA avancée et de la Science des données
L’Intelligence Artificielle avancée, la Science des données et le Machine Learning…
Ces trois avancées technologiques ?
Elles renversent la table dans l’industrie et la chaîne logistique !
La preuve ?
Leur usage s’est traduit pour un fabriquant mondial agro-alimentaire* par :
- Une diminution de 20 % des erreurs de prévision.
- Une diminution de 30 % des pertes en ventes.
- Une réduction de 50 % de la charge de travail des planificateurs de la demande.
Et bien plus encore…
De quoi redonner un large sourire à une équipe dirigeante, aux services RH, Achats, Production, Supply Chain, Sales, Comptable et aux actionnaires, vous êtes d’accord ?
Aujourd’hui ?
Ces technologies envahissent notre quotidien :
- Retargueting publicitaire
- Génétique et génomique
- Analyse des images médicales
- Recommandations de sites web
- Détection des fraudes et des risques
- Assistance virtuelle pour le service clientèle
- Planification des itinéraires des compagnies aériennes
- Gestion affinée des flux de containers de marchandises
- Développement accéléré de médicaments et de vaccins
- …
Qu’est-ce qui se cache derrière elles ? Pour quels usages dans l’industrie ? Et quels impacts pour les groupes Corporate, les ETI, PME/PMI ?
Vous êtes un décideur stratégique dans votre entreprise ?
Consultez notre guide de survie dans la jungle de ces nouvelles technologies.
Au sommaire :
- Quel est l’impact de l’Intelligence Artificielle ?
- D’où vient-elle ?
Qu’implique la Science des données ?
Quelle est l’impact de la Science des données ?
IA avancée, la Science des données et le Machine Learning sont-ils complémentaires ou adversaires ?
Réimaginer la Supply Chain avec l’IA avancée et la Science des données
Qu’est-ce que l’IA avancée ?
L’intelligence artificielle (IA) aujourd’hui ?
C’est plutôt banal.
La culture populaire associe l’IA à des robots d’apparence futuriste et à un monde dominé par les machines.
La réalité ?
L’IA est loin d’être cela.
En résumé :
L’IA vise à permettre aux machines d’effectuer des raisonnements en reproduisant l’intelligence humaine.
Simple à dire, mais complexe à mettre en œuvre.
Je m’explique…
L’objectif principal des processus d’IA est d’enseigner aux machines à partir de l’expérience. Il est donc crucial de leur fournir les bonnes informations et d’assurer leur autocorrection. Les experts en IA s’appuient sur le Deep Learning (apprentissage profond) et le traitement du langage naturel pour aider les machines à identifier des modèles et des déductions.
Pour cela, l’IA utilise des algorithmes pour effectuer des actions autonomes. Ces actions autonomes sont similaires à celles réalisées dans le passé et qui ont été couronnées de succès.
Quel est l’impact de l’Intelligence Artificielle ?
Voici un top 4 non-exhaustif :
#1 L’automatisation est facile avec l’IA :
Elle vous permet d’automatiser des tâches répétitives et à fort volume en mettant en place des systèmes fiables qui exécutent des applications fréquentes.
#2 Produits intelligents :
L’IA peut transformer des produits conventionnels en produits de base intelligents (comme les Smarts Sensors). Les applications d’IA, lorsqu’elles sont associées à des plateformes conversationnelles, des bots et d’autres machines intelligentes, peuvent donner lieu à des technologies améliorées.
#3 Apprentissage progressif :
Les algorithmes d’IA peuvent entraîner les machines à exécuter n’importe quelle fonction souhaitée. Les algorithmes fonctionnent comme des prédicteurs et des classificateurs.
#4 Analyse des données :
Puisque les machines apprennent à partir des données qui leurs sont transmises, l’analyse et l’identification des informations deviennent très importantes. Des réseaux neuronaux facilitent la formation des machines en fonction des données récoltées et analysées.
C’est maintenant qu’entre en scène la Science des données ou Data Science…
Qu’est-ce que la Science des données ?
La Science des données ?
C’est une vraie révolution !
Elle a conquis les industries du monde entier au point d’entraîner une quatrième et même cinquième révolution industrielle dans le monde d’aujourd’hui.
Elle est l’un des piliers technologiques de l’industrie 4.0 et 5.0.
D’où vient-elle ?
Elle est le résultat de la contribution de l’explosion massive des données et du besoin croissant des industries de s’appuyer sur ces données pour créer de meilleurs produits.
Nous faisons désormais partie d’une société axée sur les données. Elles sont devenues un besoin urgent pour les industries qui ont besoin d’elles pour prendre des décisions avisées et stratégiques.
Qu’implique la Science des données ?
Elle est basée sur des domaines sous-jacents comme les statistiques, les mathématiques et la programmation. Par conséquent, un scientifique des données ou Data Scientist doit les maîtriser afin de comprendre les tendances et les modèles dans les données.
Les différentes étapes et procédures de la Science des données impliquent l’extraction, la manipulation, la visualisation et la maintenance des données afin de prévoir l’occurrence d’événements futurs. Un Data Scientist doit avoir une bonne connaissance des algorithmes d’apprentissage automatique. Ces algorithmes d’apprentissage automatique relèvent de l’IA, dont nous avons parlé plus haut en détail dans cet article.
Et les industries ?
Elles ont besoin de la Science des données pour les aider à prendre les décisions nécessaires basées sur les données. Elle aide les industries à évaluer leurs performances et suggèrent également des changements nécessaires pour stimuler leurs performances.
Encore mieux ?
Elle aide aussi les équipes de développement à concevoir des produits qui plaisent aux clients en analysant leur comportement.
Quelle est l’impact de la Science des données ?
Si je vous dis Business Intelligence, cela vous parle ?
Oui, car c’est l’un des domaines influencés par la Science des données.
C’est-à-dire ?
Les Data Scientists traitent principalement les énormes quantités de données afin d’analyser les modèles, les tendances et autres. Ces applications d’analyse formulent des rapports qui sont finalement utiles pour tirer des conclusions.
Et après ?
L’expert en intelligence économique reprend là où s’arrête le Data Scientist : il utilise les rapports de la Science des données pour comprendre les données dans un domaine commercial particulier. Il présente des prévisions commerciales et des plans d’action sur la base de ces déductions.
Le plus intéressant ?
Un domaine connexe qui utilise à la fois la Science des données et les applications de veille stratégique : l’analyse commerciale. Le profil d’un analyste commercial combine un peu des deux pour aider les entreprises à prendre des décisions fondées sur les données.
Comment les Data Scientists analysent-ils cette énorme masse de données indigestes au commun des mortels ?
#1 L’analyse prédictive causale :
Les data scientists utilisent ce modèle pour dériver des prévisions commerciales. Le modèle prédictif présente les résultats de diverses actions commerciales en termes mesurables. Il peut s’agir d’un modèle efficace pour les entreprises qui tentent de comprendre l’avenir de toute nouvelle action commerciale.
#2 Analyse prescriptive :
Ce type d’analyse aide les entreprises à fixer leurs objectifs en prescrivant les actions qui ont le plus de chances de réussir. L’analyse prescriptive utilise les déductions du modèle prédictif et aide les entreprises en suggérant les meilleurs moyens d’atteindre ces objectifs.
Bon à savoir :
La Science des données utilise un large éventail de technologies orientées données, notamment SQL, Python, R et Hadoop. Cependant, elle fait également un usage intensif de l’analyse statistique, de la visualisation des données, de l’architecture distribuée, etc. pour extraire du sens des ensembles de données.
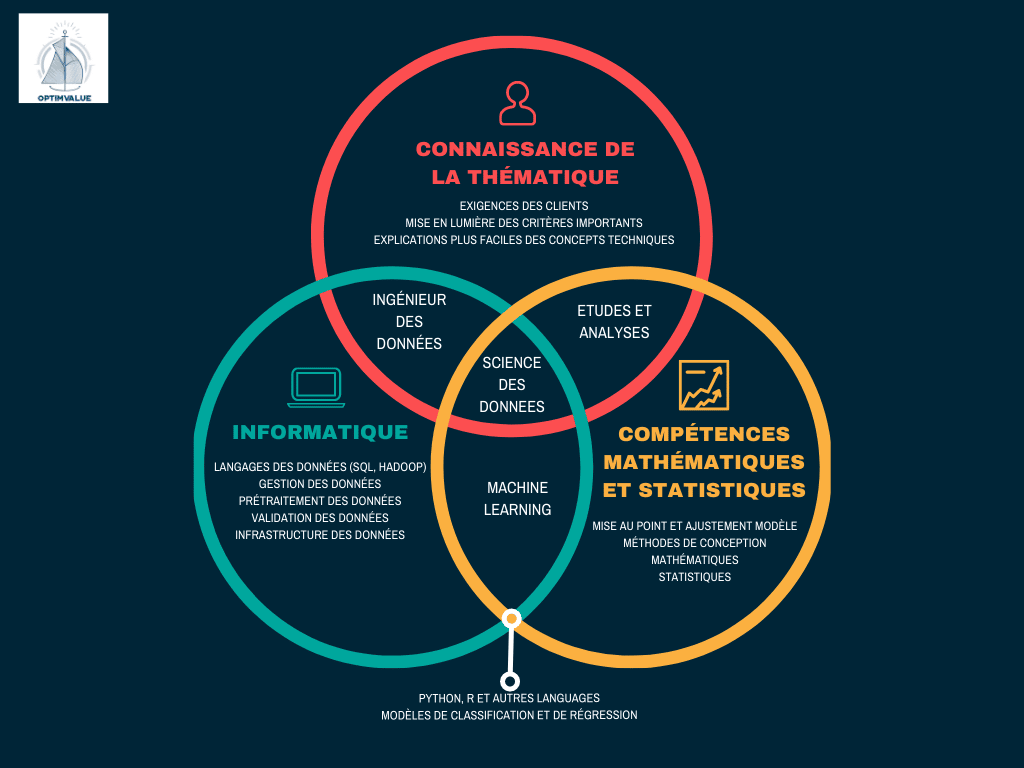
Le Machine Learning : un « surdoué » à part ?
D’où vient le Machine Learning ou apprentissage automatique ?
Il est une sous-section de l’intelligence artificielle qui permet aux systèmes d’apprendre automatiquement et de s’améliorer à partir de l’expérience. Cette aile particulière de l’IA vise à doter les machines de techniques d’apprentissage indépendantes afin qu’elles n’aient pas à être programmées pour le faire.
Pour être précis ?
La science des données couvre l’IA, qui inclut le Machine Learning qui couvre lui-même une autre sous-technologie : le Deep Learning ou l’apprentissage profond.
Le Deep Learning est une forme d’apprentissage automatique, mais il diffère par l’utilisation de réseaux neuronaux. Ce réseau stimule la fonction d’un cerveau dans une certaine mesure en utilisant une hiérarchie 3D dans les données pour identifier des modèles beaucoup plus utiles.
En résumé :
Le Machine Learning vise à permettre aux machines d’apprendre et d’exécuter n’importe quelle tâche.
Pour ce faire, il a besoin de données. Et la Science des données a besoin des retours du Machine Learning pour enrichir ses collectes et ses analyses. Aujourd’hui, ils dépendent l’un de l’autre pour divers types d’applications dans l’industrie.
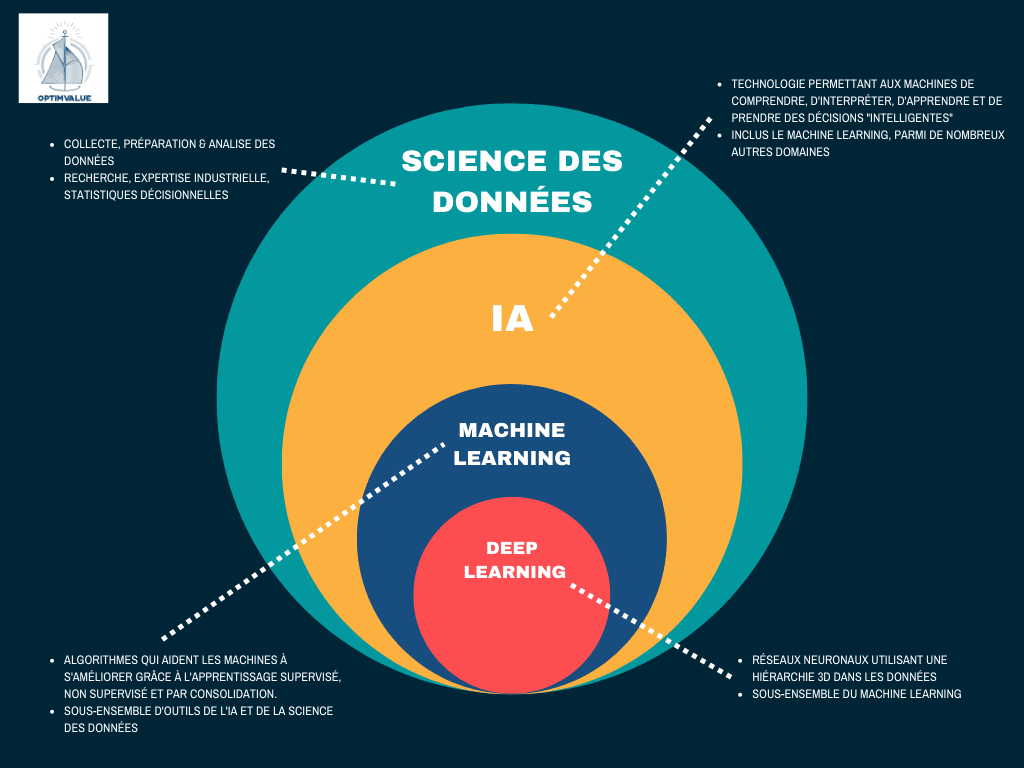
IA avancée, la Science des données et le Machine Learning sont-ils complémentaires ou adversaires ?
Ces trois technologies ?
Forment-elles un système tout-en-un ou fonctionnent-elles cloisonnées en silos ?
Revenons d’abord à leur « pourquoi » :
L’intelligence artificielle et la Science des données sont un vaste domaine d’applications et de systèmes qui visent à reproduire l’intelligence humaine par le biais de machines.
L’IA représente une rétroaction planifiée de la perception :
Perception > planification > action > rétroaction de la perception.
La Science des données utilise différentes parties de ce schéma ou de cette boucle pour résoudre des problèmes spécifiques.
Un exemple :
Dans la première étape, c’est-à-dire la perception, les Data Scientists tentent d’identifier des modèles à l’aide des données. Dans l’étape suivante, c’est-à-dire la planification, il y a deux aspects :
- Trouver toutes les solutions possibles.
- Trouver la meilleure solution parmi toutes les solutions !
C’est là qu’intervient la Science des données : Elle crée un système qui met en relation les deux points susmentionnés et aide les entreprises avancer plus vite et plus loin.
Bien qu’il soit possible d’expliquer le Machine Learning en le considérant comme un sujet à part entière, il est préférable de le comprendre dans le contexte de son environnement, c’est-à-dire le système dans lequel il est utilisé.
Le Machine Learning est le lien qui relie la Science des données et l’IA.
Comment ?
Il s’agit du processus d’apprentissage à partir de données au fil du temps. L’IA est donc l’outil qui aide la Science des données à obtenir des résultats et des solutions à des problèmes spécifiques. Et le Machine Learning est ce qui aide à atteindre cet objectif.
Le moteur de recherche de Google en est un exemple concret :
- Il est un produit de la Science des données.
- Il utilise l’analyse prédictive, un système utilisé par l’IA, pour fournir des résultats intelligents aux utilisateurs.
Regardez :
- Si une personne tape « meilleures vestes à Reims » sur le moteur de recherche de Google, l’IA recueille ces informations par apprentissage automatique.
- Maintenant, dès que la personne écrit ces deux mots dans l’outil de recherche « meilleur endroit pour acheter », l’IA entre en jeu et, grâce à une analyse prédictive, complète la phrase par « meilleur endroit pour acheter des vestes à Reims », qui est le suffixe le plus probable de la requête que l’utilisateur avait à l’esprit.
Maintenant, comment ces technologies travaillent-elles pour la Supply Chain ?
Réimaginer la Supply Chain avec l’IA avancée et la Science des données
Un défi constant dans l’industrie ?
Ce sont les pertes !
Celles dues au surstockage ou au sous-stockage des stocks :
- Le surstockage entraîne souvent des gaspillages et une baisse des marges.
- Le sous-stockage peut se traduire par des pertes de ventes, de revenus et de clients.
Grâce à l’IA, les fabricants peuvent :
- Suivre les opérations de l’atelier de production.
- Fournir des prévisions de la demande plus précises
- Réduire les pertes liées aux stocks et simplifier la gestion des ressources
Un exemple concret d’adoption réussie cité en introduction :
Le groupe Danone a mis en place un système de Machine Learning afin de réaliser de meilleures prévisions de la demande. L’entreprise avait besoin de prévisions plus précises et plus sûres, en raison de la courte durée de conservation de ses produits frais et de la volatilité de la demande.
Plus de 30% du volume total est vendu par le biais d’offres promotionnelles telles que des remises et des prospectus, de sorte que les prévisions de la demande étaient quelque peu ad hoc.
Le système de Machine Learning mis en œuvre n’a pas seulement amélioré les prévisions, mais aussi la planification entre les différents départements tels que les ventes, la chaîne d’approvisionnement, les finances et le marketing. Ce système a amélioré l’efficacité et l’équilibre des stocks, permettant à Danone d’atteindre ses niveaux de service cibles pour les stocks au niveau des canaux ou des magasins.
Résultats ?
- Amélioration de la précision au fil du temps : De meilleures prévisions sont faites au fil du temps, car les algorithmes d’apprentissage automatique apprennent à partir des données existantes.
- Amélioration de la satisfaction des clients : Lorsque les produits sont « en rupture de stock », cela diminue la satisfaction des clients, alors que la satisfaction des clients augmente lorsque les produits sont toujours disponibles. Cela améliore la fidélité des clients et la perception de la marque.
- Amélioration de la planification des effectifs : La prévision de la demande peut aider le service RH à faire des choix efficaces entre le personnel à temps plein et le personnel à temps partiel, optimisant ainsi les coûts et l’efficacité des ressources humaines.
- Amélioration de l’optimisation de la démarque et des rabais : Les ruptures de stock sont une situation courante pour les entreprises de vente au détail, où les produits restent invendus pendant une période plus longue que prévu. Cela entraîne souvent des coûts de stock plus élevés que prévu et le risque que les produits deviennent obsolètes et perdent de la valeur. Dans ce scénario, les produits sont vendus à des prix de vente inférieurs. Avec la prévision de la demande, ce scénario peut être minimisé.
- Efficacité globale : Avec la prévision de la demande, les équipes peuvent se concentrer sur les questions stratégiques au lieu d’essayer de réduire ou d’augmenter les stocks et les effectifs.
Chez Danone, l’utilisation combinée de l’IA avancée, de la Science des données et du Machine Learning a permis d’atteindre les résultats exceptionnels mentionnés dans l’introduction* de cet article.
Quelle transformation digitale pour vous et votre entreprise ?
Que vous soyez dirigeants dans un groupe Corporate, d’une ETI, PME, PMI, il existe des moyens concrets :
- De surmonter vos défis opérationnels.
- De gagner en productivité, en capacité de traitement et en qualité.
- De vous aider à réduire vos coûts, vos risques, le gaspillage.
Et si nous en parlions ensemble ?





